
Inspecting utterances#
Searching utterances#

You can search for specific utterances either by file, speaker, or text. The text search has the capability of using regular expressions. Additionally, you can use the replace field to replace all instances of a text query with another string in the corpus. Replacements can also include regular expressions references such as \1 to refer to groups in the search expression. See the Python regular expression documentation for more details.
Utterance search results#

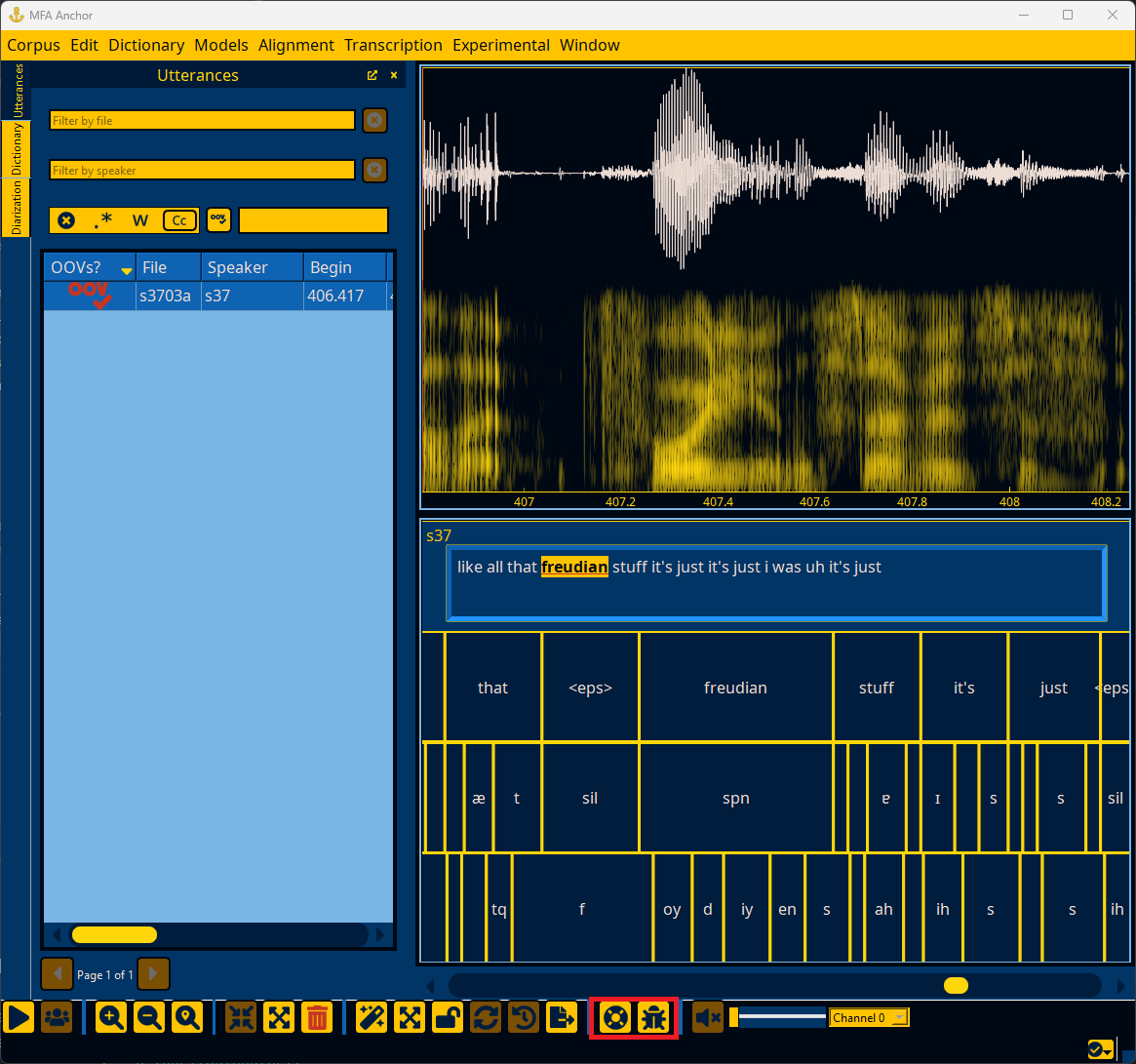
The table of utterances contains all search results (or all utterances if there are no filters), and can be sorted according to each column. The columns contain information about whether it has an OOV (if a pronunciation dictionary has been loaded), the file, speaker, begin, end, duration, and text by default. By right clicking on the table header, additional columns can be viewed, though they are only relevant once steps like alignment, transcription, or loading ivectors have been done.

Utterance details#

The top right of the Anchor window contains the waveform and spectrogram for the currently selected utterance.
Note
See Configuring the spectrogram and Configuring pitch tracks for options related to spectrogram and pitch track display.

The bottom left of the Anchor window contains the text transcription of the currently selected utterance, along with additional tiers if steps like alignment or transcription have been performed. Right clicking on an interval (outside of any text boxes for the transcription) allows for changing the speaker of the utterance or making tiers visible/hidden.
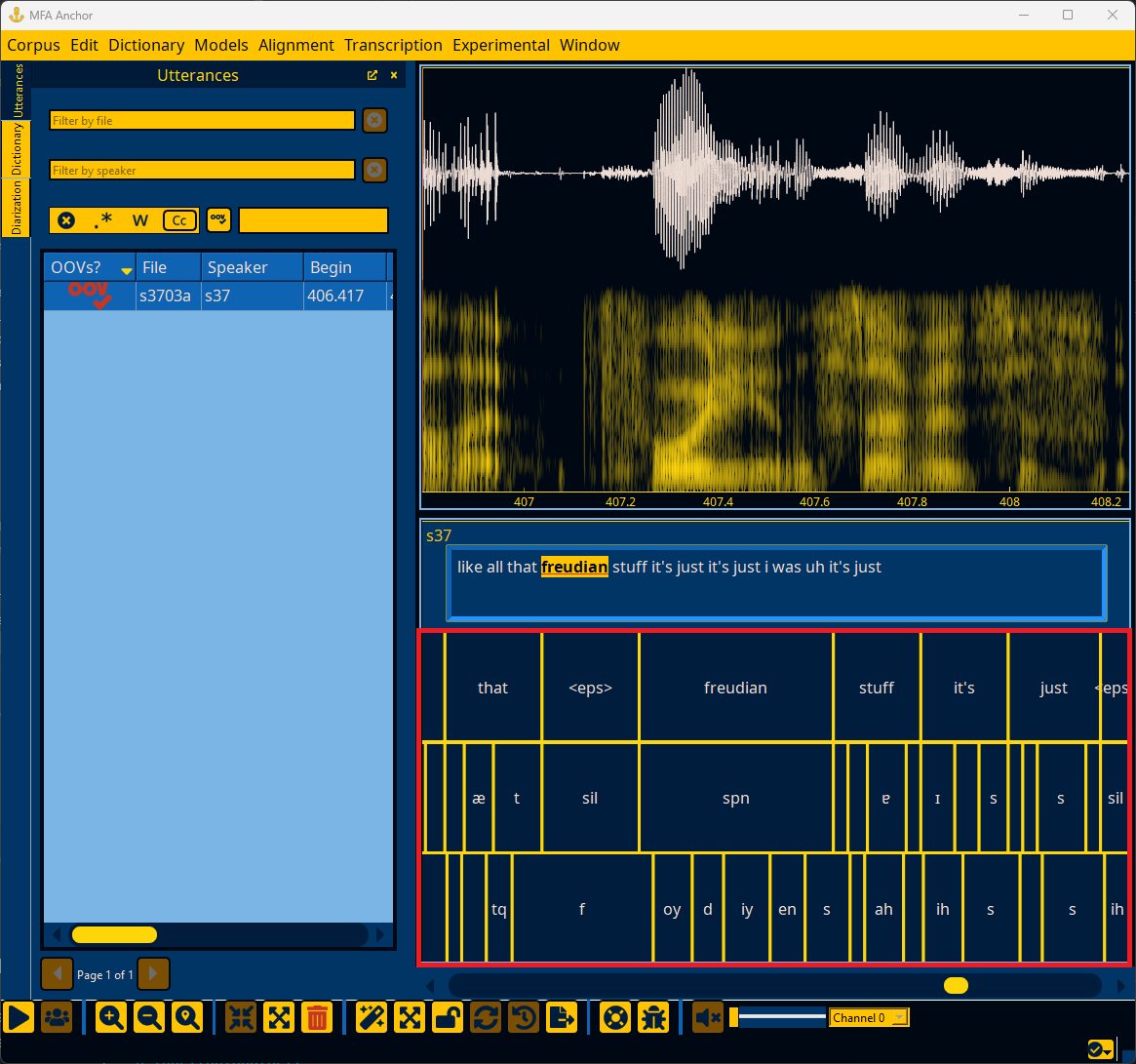
Utterance context menus#
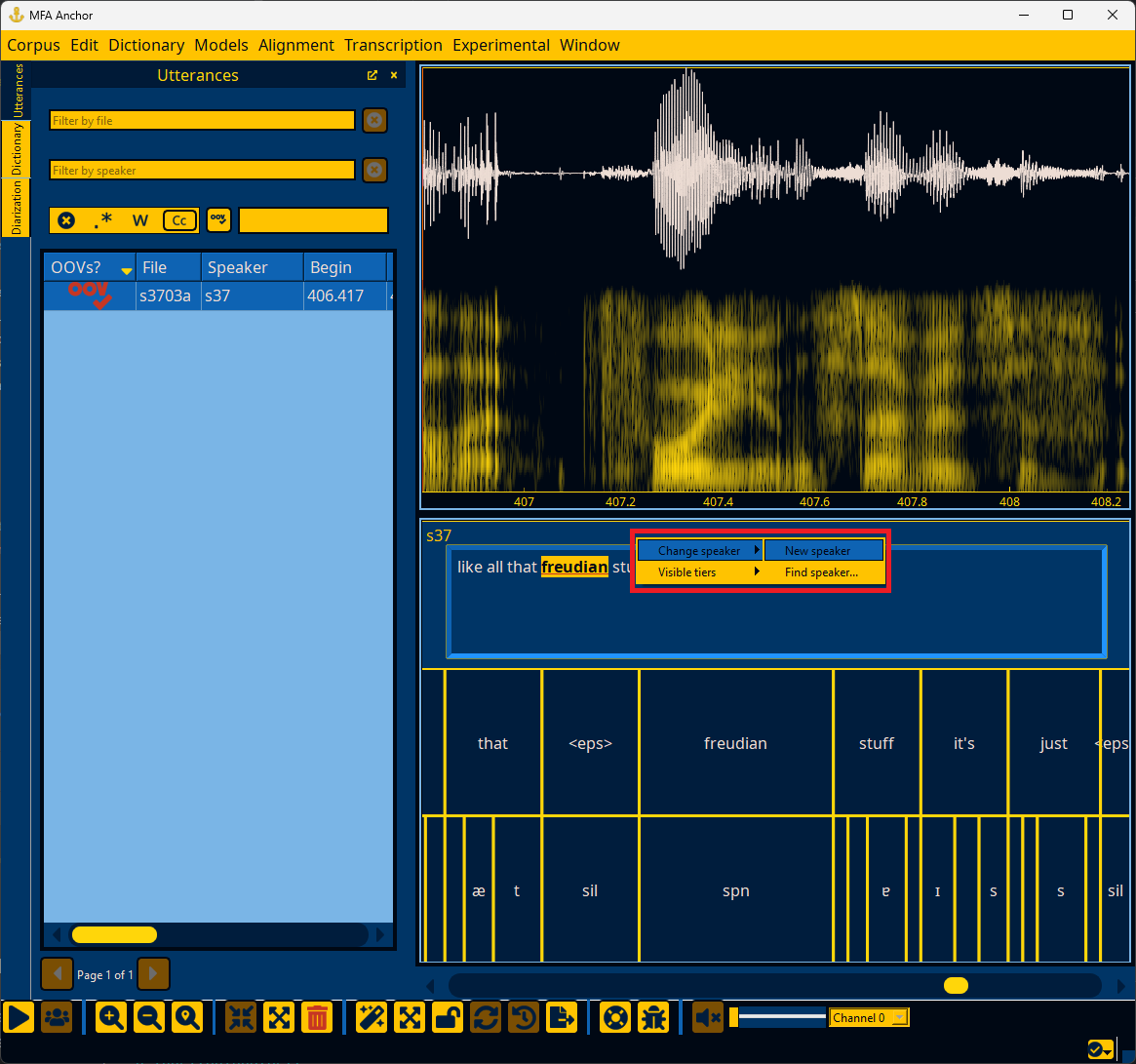
Right-clicking on an utterance outside of the transcript edit box will bring up a context menu for changing the utterance’s speaker or changing the visibility of tiers.
You can change the speaker for a given utterance either by selecting a speaker that is already in the file or by specifying a speaker via “Find speaker…” that will bring up a dialog to search speaker names.
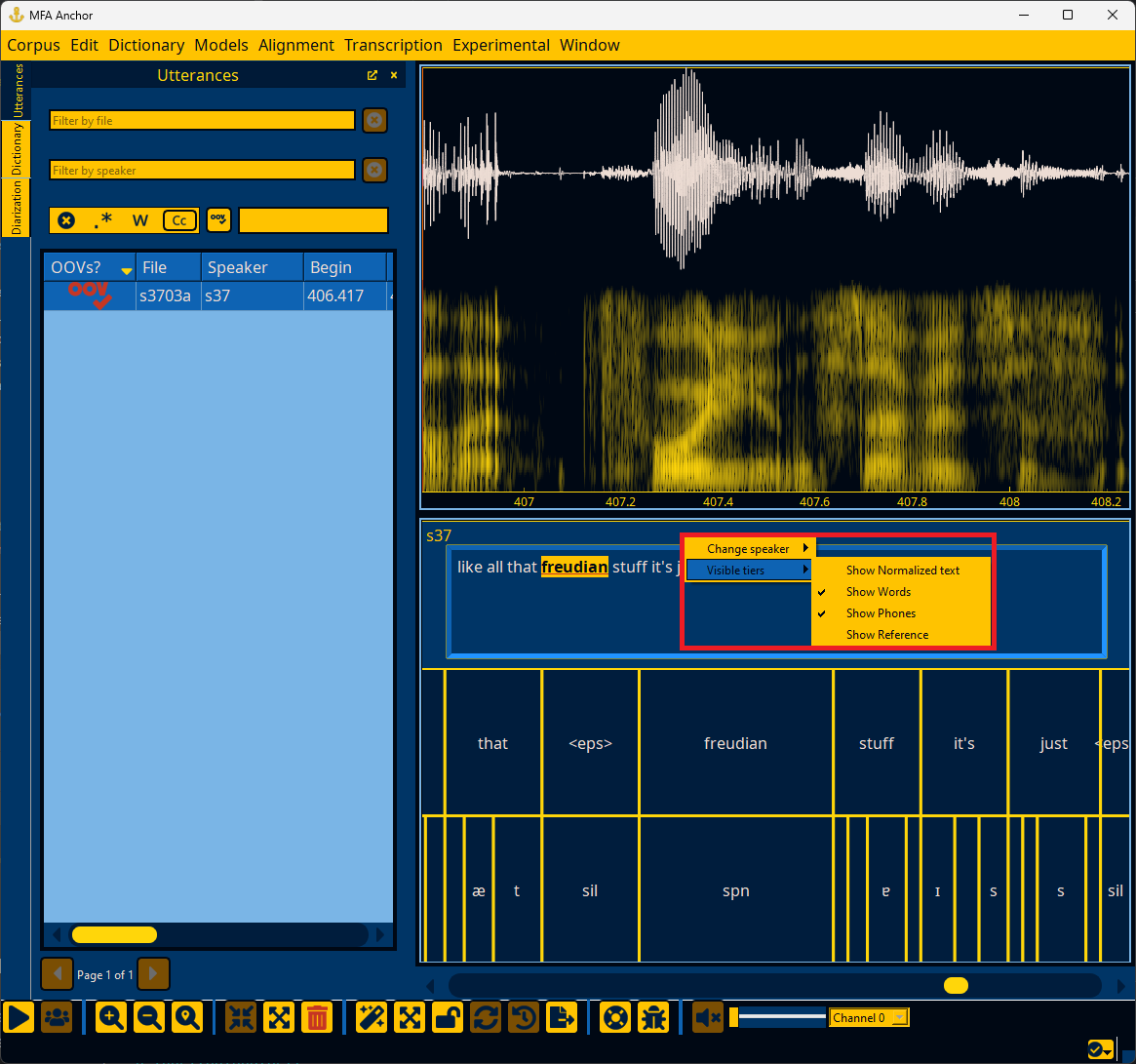
You can show/hide tiers for alignment/transcription via the context menu as well. By default, only text and normalized text are available, but by following the steps in Spot-checking alignment or Transcribing utterances, more tiers will be listed. Normalized text is by default hidden, as it is a calculated field based on the text. Normalized text is what is used as input to alignment as it will perform MFA’s clitic analysis or Spacy tokenization.
Toolbar#
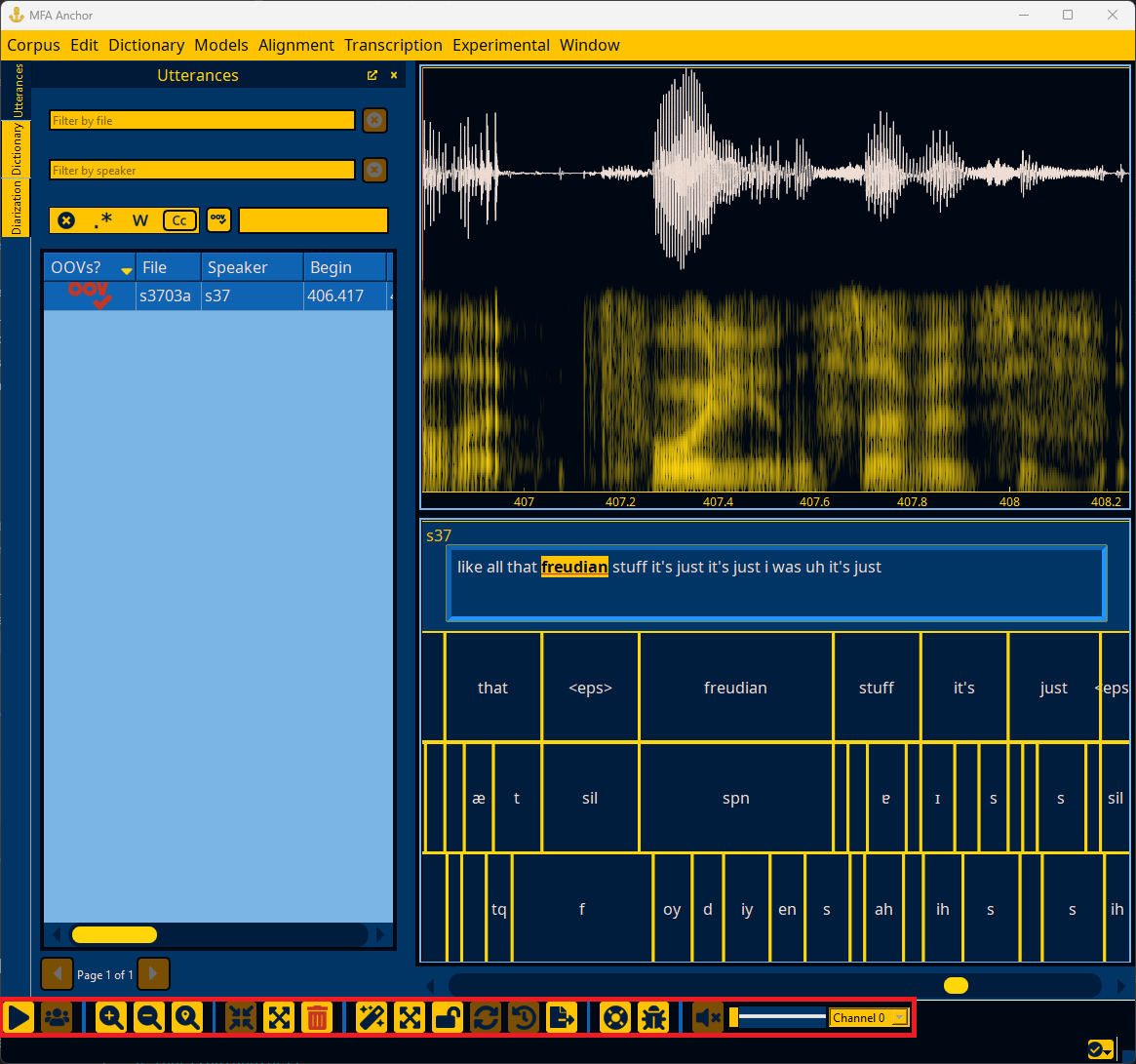
The toolbar at the bottom of the Anchor window provides a number of common actions for inspecting, editing, and transforming utterances.
The toolbar contains multiple sections for various types of common actions. Note that these actions also have keyboard shortcuts that can be viewed and customized by Configuring Anchor.
Utterance playback#

The primary action in this section is for playing/pausing the audio (/), by default the keyboard shortcut is tab.
Navigating files#

The utterance view can be zoomed in (), zoomed out (), or zoomed to the current selection (). Zooming can be done via ctrl+mouse wheel in addition to the keyboard shortcuts in Configuring Anchor. Panning can be done via the mouse wheel, keys in Configuring Anchor, and via the scrollbar below the spectrogram.
Editing utterances#

Utterances can be split in half (), merged into a single utterance (), or deleted ().

The advanced functionality is only available when an acoustic model and pronunciation dictionary have been loaded, as they perform alignment. The alignment action () generates an alignment for the utterance, and the segmentation action () splits the utterance based on VAD and what gets aligned in each segment VAD returns.
The alignment action is similar to MFA’s align_one command and the segmentation action is similar to MFA’s segment command.
Help#
There are two help actions in the toolbar for opening up Anchor documentation () and reporting any issues you’ve encountered while using Anchor ().
Utterance audio output#
